GNN学习笔记
GNN从入门到精通课程笔记
2.3 Node2Vec (KDD ‘16)
- node2vec: Scalable Feature Learning for Networks (KDD ‘16)
Abstract
- Learn a mapping of nodes to a low-dimensional space of features
- We define a flexible notion of a node’s network neighborhood and design a biased random walk procedure, which efficiently explores diverse neighborhoods.
- task-independent representations in complex networks
Introduction
- representation learning
- informative, discriminating, and independent features
- to learn feature representations by solving an optimization problem
- defining an objective function
- DeepWalk: rely on a rigid notion of a network neighborhood, which results in these approaches being largely insensitive to connectivity patterns unique to networks
- Design Goal: homophily + structural equivalence
- Ours:
- 2nd order random walk approach
- Can learn representations that organize nodes based on their network roles and/or communities they belong to.
- Flexible, giving us control over the search space through tunable parameters.
Related Work
- Hand-crafted features
- Dimensionality reduction technique
- Laplacian and the adjacency matrices
- Hard to scale for large networks
- Representation learning: Skip-gram
- DeepWalk: no flexible
- Supervised feature learning: directly minimize the loss function for a downstream prediction task
Feature Learning Framework
- Skip-gram: 中间词预测周围词
- Conditional independence: 可以用马尔可夫链
- Symmetry in feature space: 可以用 softmax
- negative sampling
- Hierarchical Softmax
- Classic search strategies
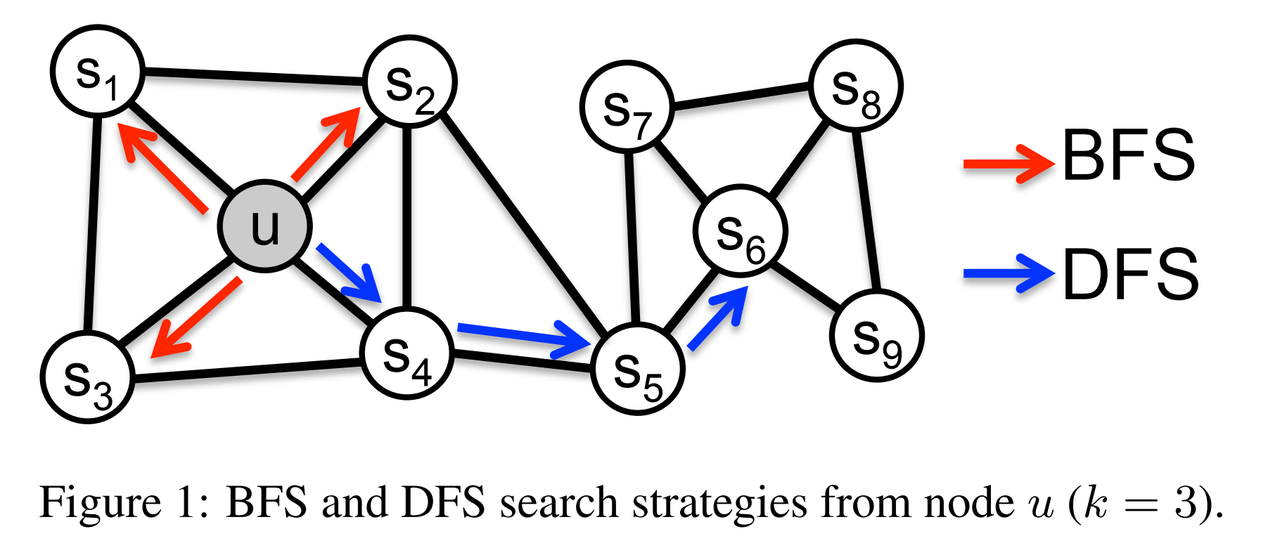
- BFS(Breadth-first Sampling ): structural equivalence
- DFS(Depth-first Sampling): homophily (high variance)
- In the real-world, these equivalence notions are not exclusive; networks commonly exhibit both behaviors where some nodes exhibit homophily while others reflect structural equivalence.
- node2vec
- 2nd order random walk
- Search bias alpha
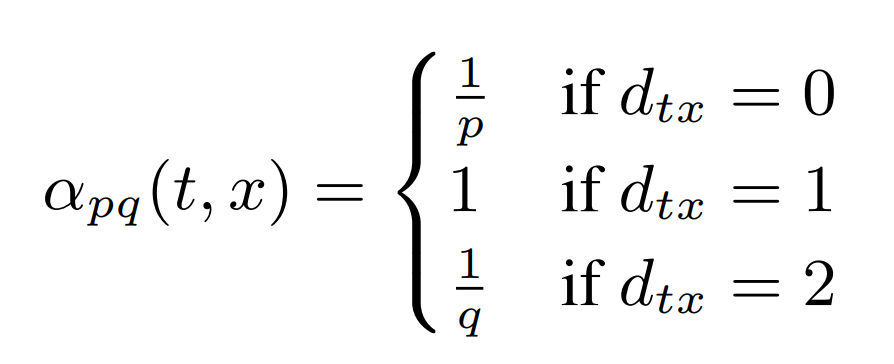
- 0: 返回(从当前节点v走完这一步之后,距离上一节点t的距离为0)
- 1: 徘徊(从当前节点v走完这一步之后,距离上一节点t的距离为1)
- 2: 远行(从当前节点v走完这一步之后,距离上一节点t的距离为2)
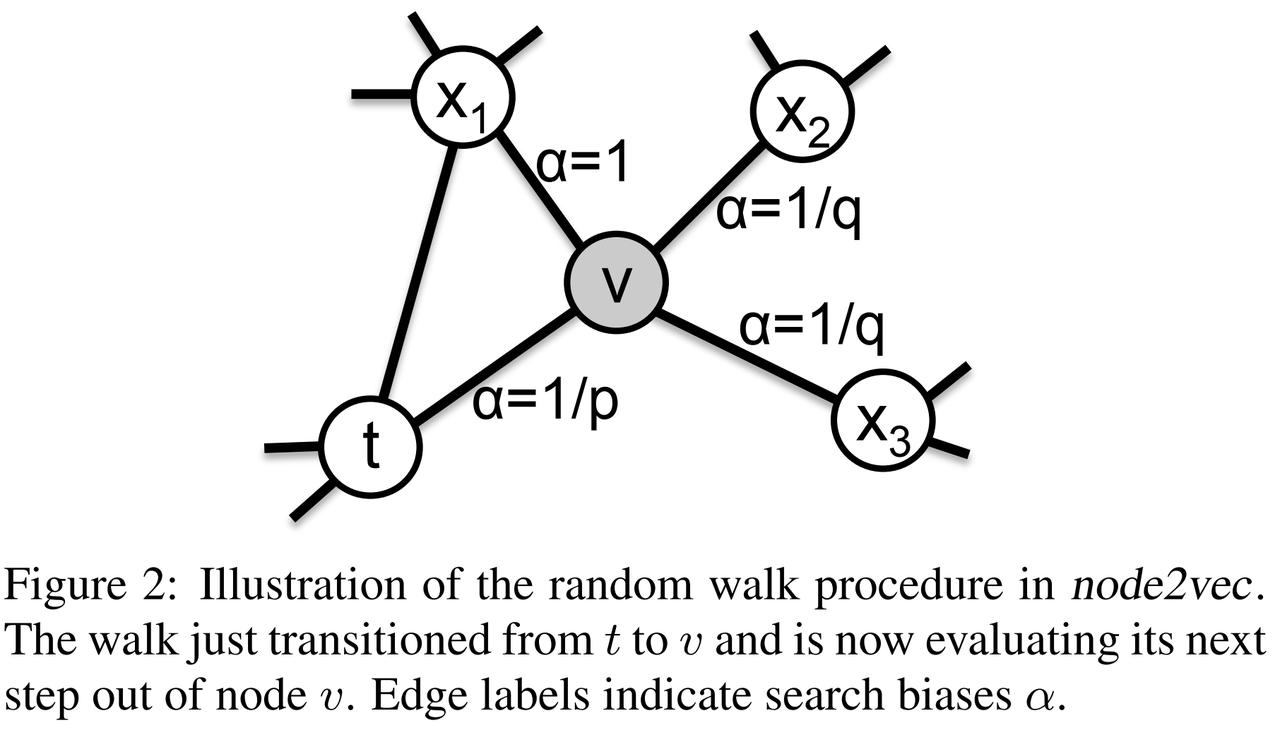
- p: return parameters (p大, DFS, 深度优先,探索远方)
- q: In-out parameter(q大,BFS,宽度有限,探索近邻)

- Preprocessing: O(n)
- AliasSample: O(1)采样
- Learning edge feature

- Experiments
- Multi-label classification: 通过已知节点的信息的label来预测未知节点的label
- Comment
- 需要大量随机游走序列训练
- 距离较远的两个节点无法直接相互影响,看不到全图信息
- 无监督,仅编码图的连接信息,没有利用节点的属性特征